고령자의 한국어 음성을 잘 인식하는 음성인식기를 개발하는데 필요한 대용량 고령자 음성 데이터를 공개한다. 본 데이터셋은 대한민국 과학기술정보통신부(MSIT)와 정보통신기획평가원(IITP)의 지원을 받아 마인즈랩(MINDs Lab)과 한국전자통신연구원(ETRI)이 협력하여 구축하였다.
구축 배경
일반적인 음성인식 엔진은 표준어를 기반으로 음성데이터와 이를 전사한 텍스트데이터를 하나의 데이터 셋으로 만들어 음성인식 학습엔진에 입력하여 학습한다. 이러한 학습의 결과로 만들어진 음성인식모델은 표준어를 사용하는 사람들의 발화는 잘 인식하지만 발음이 부정확한 사람(노약자, 어린이 등)의 발화는 상대적으로 잘 인식하지 못한다. 일반적인 음성인식 엔진이 부정확한 발음의 음성을 인식할 때에는 입력된 음성의 특징을 추출하고 이를 음성인식모델을 통해 가장 확률이 높은 단어와 매핑하여 결과를 산출하게 된다. 학습데이터로 활용한 음성 및 텍스트의 분량과 일관성이 음성인식 성능에 가장 큰 영향을 미치는 요인이 되는 것이다. 따라서, 고령자의 음성을 보다 잘 인식하기 위해서는 인식 대상인 고령자의 음성데이터를 구축하여 인식기를 훈련해야 한다.
MINDsLab-ETRI VOTE400은 고령자와 로봇 간 원활한 음성 교류를 가능하게 하는 음성인식모델을 개발하기 위하여 수집 확보한 대용량 고령자 한국어 음성데이터이다.
소개
본 데이터셋은 고령자 대화체 음성데이터와 낭독체 음성데이터로 구성되어 있다. 본 음성데이터의 수집을 위해 보건복지부의 위탁을 받아 전국 독거노인에게 종합적인 서비스를 제공하는 독거노인종합지원센터의 지원을 받았다.
대화체 음성데이터
대화체 음성데이터 구축을 위해 약 3천명 이상의 고령자 참여자들로부터 800시간 이상의 원시 음성데이터를 수집하였다. 음성을 제공한 고령자는 성별, 지역별, 연령대별로 균등하게 분배함으로써 결과적으로 학습데이터에 가급적 다양한 특성이 반영되도록 하였다. (그림1 참고)
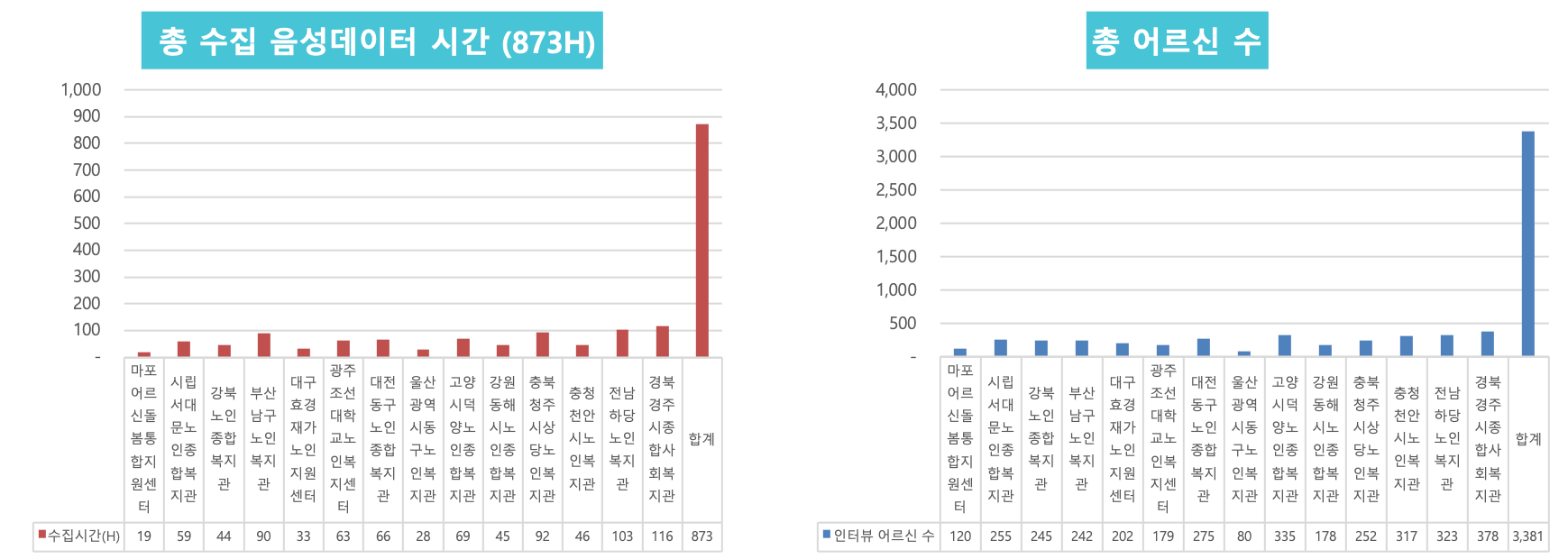
원시 음성데이터를 가공 정제하여 최종적으로 300시간의 학습데이터를 확보하였다. 학습데이터는 전사 후 1차, 2차 검수의 다단계 검증을 통해 높은 품질과 일관성을 확보하였다.
낭독체 음성데이터
대화체 음성데이터는 평상 시 발화에 가장 가까운 데이터이므로 음성인식기 훈련에 최적이지만 데이터의 정확성과 품질은 부족함이 있다. 말에 실수가 있거나 발음이 불명확한 문장들도 많이 있고, 고령자의 음성 뿐 아니라 상담자의 음성도 섞여 있기 때문이다. 낭독체 음성데이터는 고령자 참여자들에게 발화할 문장을 제시하여 읽게 하고 그 음성을 녹음하고, 녹음한 음성을 사람이 직접 확인한 뒤 문제가 있는 경우 재녹음하는 방식의 데이터 수집 과정을 통해 데이터 오류를 최소화한 고품질 음성데이터이다. 낭독체 음성데이터는 대화체 음성데이터에 포함된 오류로 인해 음성인식 모델의 성능이 저하되는 현상을 완화함으로써 보다 높은 성능의 음성인식 성능을 획득하는데 활용할 수 있으리라 기대한다. VOTE400은 총 100시간 분량의 낭독체 음성데이터를 포함한다.
데이터 구성
VOTE400 데이터셋은 음성데이터와 전사데이터의 쌍으로 구성된다. 음성데이터는 16bit MONO PCM 데이터로서 WAV 파일에 저장했다. 전사데이터는 ANSI 인코딩의 텍스트 파일에 저장했다. 음성데이터와 그에 대응하는 전사데이터는 각각 동일한 파일 이름으로 저장되어 있다.
VOTE400 데이터셋은 1차, 2차, 3차 데이터셋으로 이루어지며, 그 구성은 다음과 같다.
1차 대화체 음성 데이터셋
데이터는 총 11개의 폴더에 나누어 저장되어 있으며, 각 폴더는 수집 지역명(편의상 구분)으로 만들었다. 지역별 음성데이터 구성은 다음과 같다.
| 지역(폴더명) | 음성 길이 | 데이터량(GB) |
|---|---|---|
| 강북 | 15시간 | 1.62 |
| 고양 | 20시간 19분 | 2.18 |
| 광주 | 25시간 18분 | 2.92 |
| 대구 | 12시간 30분 | 1.35 |
| 대전 | 40분 | 0.07 |
| 마포 | 6시간 13분 | 0.69 |
| 부산 | 31시간 6분 | 3.40 |
| 울산 | 19시간 39분 | 2.11 |
| 전남 | 12시간 23분 | 1.35 |
| 충북 | 5시간 35분 | 0.61 |
| 충청 | 1시간 33분 | 0.17 |
| 합계 | 150시간 19분 | 16.4 |
2차 대화체 음성 데이터셋
데이터는 총 11개의 폴더에 나누어 저장되어 있으며, 각 폴더는 수집 지역명(편의상 구분)으로 만들었다. 지역별 음성데이터 구성은 다음과 같다.
| 지역(폴더명) | 음성 길이 | 데이터량(GB) |
|---|---|---|
| 강북 | 16시간 25분 | 1.76 |
| 강원 | 26시간 30분 | 2.84 |
| 광주 | 0시간 26분 | 0.05 |
| 대구 | 3시간 54분 | 0.43 |
| 대전 | 32시간 51분 | 3.52 |
| 서대문 | 2시간 42분 | 0.30 |
| 부산 | 26시간 13분 | 2.81 |
| 전남 | 11시간 18분 | 1.21 |
| 충북 | 0시간 24분 | 0.04 |
| 경주 | 19시간 46분 | 2.12 |
| 고양 | 10시간 24분 | 1.11 |
| 합계 | 150시간 19분 | 16.2 |
3차 낭독체 음성 데이터셋
음성데이터는 지역별로 다른 폴더에 구분하여 저장하였다. 지역별 음성데이터 구성은 다음과 같다.
| 지역 | 음성 길이 | 참여 인원(명) | 데이터량(GB) |
|---|---|---|---|
| 서울 | 17시간 39분 | 10 | 5.22 |
| 강원 | 20시간 19분 | 10 | 4.85 |
| 대구 | 25시간 18분 | 12 | 7.94 |
| 밀양 | 12시간 30분 | 10 | 5.90 |
| 전라 | 40분 | 10 | 5.91 |
| 합계 | 101시간 | 52 | 30.00 |
다운로드
데이터셋의 사용을 위해서는 사용허가 협약서의 내용을 숙지하시고 협약에 동의하셔야 합니다.
동의하신다면 아래 사용허가협약서와 용도설명서를 작성하여 서명하신 후 스캔한 PDF 문서를 아래 안내해 드리는 담당자에게 이메일로 보내주시기 바랍니다.
협약자 정보와 용도가 협약 사항에 부합하는 경우 본 데이터셋을 제공합니다.
담당자 연락처
- 이름: 장민수 책임연구원
- 이메일: minsu(at)etri.re.kr
- 전화번호: 042-860-1250
- 소속: 한국전자통신연구원 지능로보틱스연구본부 인간로봇상호작용연구실
주의
- 본 데이터셋은 개인정보보호와 안전한 데이터의 획득/관리를 위해 기관생명윤리위원회(IRB: Institutional Review Board)의 승인을 거쳐 구축되었습니다.
- 본 데이터셋은 과학기술정보통신부 산하 정보통신기획평가원의 “고령 사회에 대응하기 위한 실환경 휴먼케어 로봇 기술 개발(2017-0-00162)” 사업의 일환으로 구축되었습니다.